
株式会社アプリズムは、フィジカルAIの推進企業として、現実世界で動作するAI技術の研究開発に取り組んでいます。
その中核となる VLM(Vision-Language Model:視覚言語モデル)と VLA(Vision-Language-Action:視覚言語行動モデル) の違いについて、
当社の実例を交えながらわかりやすく解説します。
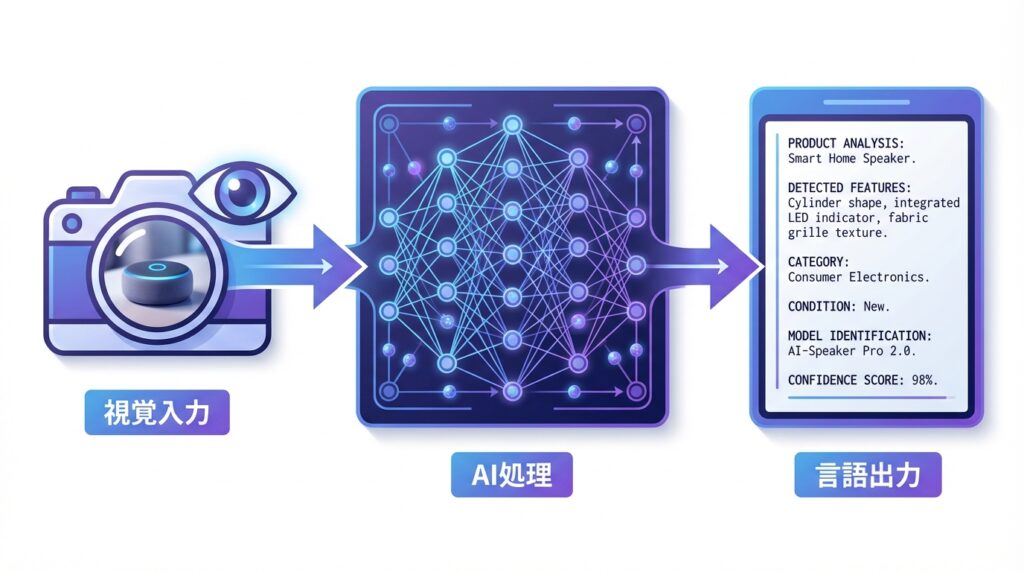
◆VLM(Vision-Language Model)とは?
VLM(Vision-Language Model:視覚言語モデル)は、画像や動画などの視覚情報とテキストなどの言語情報を統合的に処理できるAIモデルです。
VLMの主な特徴
・視覚と言語の統合処理:画像を見て、その内容をテキストで説明することができます
・マルチモーダル理解:画像認識と大規模言語モデル(LLM)の技術を組み合わせています
・出力は言語情報:理解した内容を文章やテキストとして出力します
アプリズムのVLM活用事例
【事例1】画像認識AIを用いたラベル位置検査システム
株式会社アプリズムでは、CLIPとDINOv2という2つのVLMを活用した製造ラインの品質検査システムを開発しました。

背景と課題
お酒や飲料の製造ラインで発生する「ラベルのずれ」の検査は、自動化が難しい課題でした。
従来は人の目視に頼っており、生産効率と品質の安定性に課題がありました。
VLM技術の活用
CLIP(OpenAI開発のマルチモーダル基盤モデル):ほぼタイムラグなしで推論を実行
DINOv2(Meta開発の自己教師あり学習CVモデル):正解・不正解画像の類似度の差が明確
実証実験の成果
Raspberry Pi上で動作するエッジAIとして実装し、正解ラベルと不正解ラベルを高精度で識別することに成功しました。
これにより、「見て理解する」VLMの能力を実証しました。
重要なポイント
このシステムは「ラベルのずれを検出して報告する」ことはできますが、「ラベルを正しい位置に貼り直す」という物理的な行動は行いません。
これがVLMの特性です。
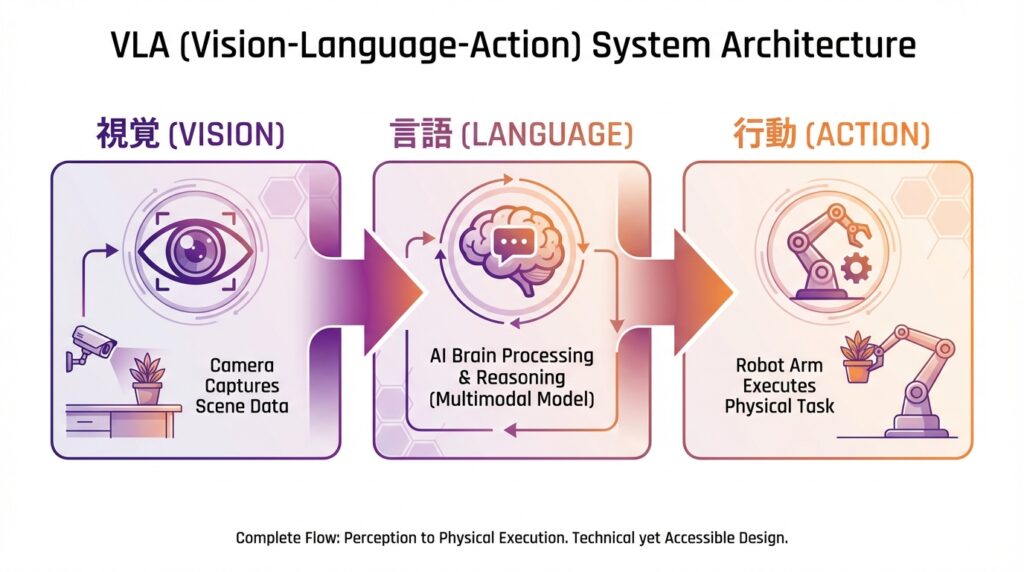
◆VLA(Vision-Language-Action)とは?
VLA(Vision-Language-Action:視覚言語行動モデル) は、視覚、言語、そして「行動」の3つの要素を統合的に処理するマルチモーダルモデルです。
VLMの機能を拡張し、物理的な行動の実行まで可能にした次世代のAI技術です。
VLAの主な特徴
・視覚・言語・行動の統合:見て、理解して、実際に行動します
・行動計画の立案:認識した情報を基に具体的なアクションを計画します
・物理的実行能力:ロボットなどを通じて現実世界で行動を実行します
・フィジカルAIの中核技術:サイバー空間と現実世界を融合させる技術です
アプリズムのフィジカルAI推進
株式会社アプリズムは、VLA技術を含むフィジカルAIの推進に注力しています。
フィジカルAIとは
現実世界(フィジカル空間)の物理法則を理解し、周囲の環境に適応しながら自律的に行動できるAI技術です。
センサーネットワークを通じて現実世界の情報を収集し、サイバー空間で高度に分析し、
その結果を再び現実世界へフィードバックする一連のサイクルを実現します。
アプリズムの技術基盤
・技術者110名体制のうち25名がAI関連の専門家
・機械学習(Machine Learning)、深層学習(Deep Learning)
・エッジコンピューティング(Edge Computing)
・フィジカルAI(Physical AI)
・生成AI、RAG AIエージェント
産官学連携による研究開発
大手メーカー様の先端技術研究部署、各大学、国立研究所(産総研)との共同研究・受託開発・実証実験を通じて、VLA技術の実用化に取り組んでいます。
VLMとVLAの決定的な違い
| 項目 | VLM(Vision-Language Model) | VLA(Vision-Language-Action) |
|---|---|---|
| 処理要素 | 視覚 + 言語(2つのモダリティ) | 視覚 + 言語 + 行動(3つのモダリティ) |
| 出力 | テキスト・説明文・分析結果 | 物理的なアクション・制御信号 |
| 目的 | 理解と説明・検出と報告 | 理解と行動の実行 |
| 実行能力 | 言語情報の生成のみ | 現実世界での行動実行 |
| 主な用途 | 画像認識、品質検査、異常検知 | ロボット制御、自動運転、物理作業 |
| アプリズムの事例 | ラベル位置検査システム | フィジカルAIソリューション開発中 |
| 一言で表すと | 「分かるAI」 | 「動けるAI」 |
製造現場での違いを例に
VLMの役割(現状のアプリズムシステム)
1.カメラでラベルを撮影
2.VLMがラベルのずれを検出
3.「ラベルが3mm右にずれています」と報告
4.人間が修正作業を行う
5.VLAの役割(フィジカルAIの未来)
VLAの役割(フィジカルAIの未来)
1.カメラでラベルを撮影
2.VLAがラベルのずれを検出
3.ロボットアームを制御してラベルを正しい位置に貼り直す
4.作業完了を報告
最大の違いは「行動を実行するかどうか」です。
技術的な発展の流れ
LLM(言語のみ)
↓
VLM(視覚 + 言語)← 理解と説明【アプリズムの現在地】
↓
VLA(視覚 + 言語 + 行動)← 理解と実行【アプリズムが目指す未来】
株式会社アプリズムは、VLMの実装実績を基盤に、VLAを含むフィジカルAI技術へと進化を続けています。
アプリズムが提供する価値
- 「部分最適」から「全体最適」へ
個別の工程だけでなく、システム全体を俯瞰した最適化を実現 - あらゆる社会システムの効率化
製造、物流、インフラ管理など多様な領域で生産性を向上 - 新産業の創出
現実世界のデータを活用した新たなビジネスモデルの構築 - 知的生産性の向上
人間の創造的業務への集中を可能にするインテリジェントな自動化
VLAが注目される理由
- 柔軟な適応力
従来の固定プログラムと異なり、新しい状況やタスクに迅速に対応できます。 - 自然言語での指示が可能
「この作業をして」といった自然な言葉だけで、ロボットが新しいタスクに対応できます。 - セットアップコストの削減
専門エンジニアによる複雑なプログラミングが不要になります。 - フィジカルAIの実現
AIが仮想空間から現実世界へと活動範囲を広げる重要な技術です。
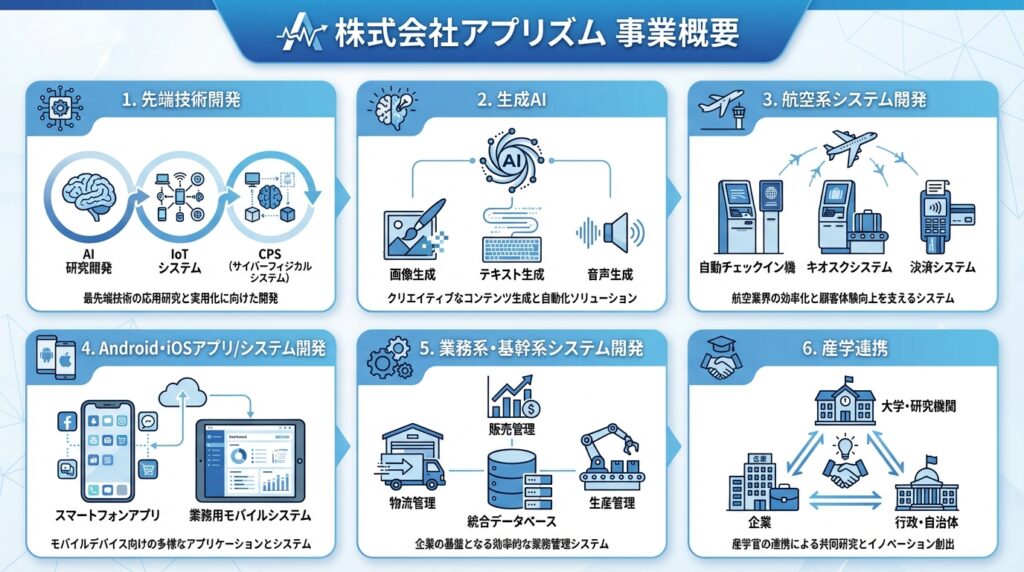
アプリズムの実績と強み
・AI関連実績
・音声認識:自然言語処理技術の実装
・画像認識:CLIP、DINOv2を活用した検査システム
・導線分析:人やモノの動きを可視化・最適化
・異常検知:馬の異常検知プロダクト「aiba」など
・エッジAI:Raspberry Pi上での生成AI実装
開発体制
・AI専門家25名を含む技術者110名体制
・概念検証(PoC)から論文調査、実装まで一貫したソリューション提供
・大手メーカー、大学、国立研究所との産官学連携
技術スタック
・機械学習・深層学習
・エッジコンピューティング
・フィジカルAI
・生成AI・RAG・AIエージェント
・IoT・CPS(サイバーフィジカルシステム)
まとめ
・VLMは画像を見て理解し、説明することに優れた「認識と言語化」のAI
・アプリズム事例:ラベル位置検査システム(CLIP・DINOv2活用)
・VLAはVLMの能力に加えて、実際に行動を起こせる「実行型」のAI
・アプリズムの取り組み:フィジカルAIの研究開発推進
・最大の違い:「説明するだけ」か「行動もできる」か
株式会社アプリズムは、VLM技術の実装実績を活かしながら、VLAを含むフィジカルAI技術の推進を通じて、現実世界とデジタル世界を融合させた新たな価値創造に挑戦し続けています。
お問い合わせ
VLM・VLA技術、フィジカルAIに関するご相談は、株式会社アプリズムまでお気軽にお問い合わせください。
株式会社アプリズム AIプロダクト本部
〒542-0081 大阪府大阪市中央区南船場2丁目9-8
シマノ・住友生命ビル1階(総合受付)・2階
Tel:06-4708-8959
Email:aisol@apprhythm.co.jp
URL:https://www.apprhythm.co.jp/